whatifd¶
Open experiment runner for LLM behavior changes. Fork production traces, replay with a proposed change, score the diff, emit a PR-ready verdict report.

60-second demo¶
No Langfuse, no Anthropic key, no production traces. Three files, one command, real ReportV01 JSON + Markdown verdict:
uv pip install whatifd whatifd-langfuse whatifd-inspect-ai
# 1. Tiny runner — the boundary you'd implement against your real agent.
mkdir -p demo && cat > demo/runner.py <<'EOF'
from whatifd.contract import TraceInput, ReplayConfig, ToolCache, ReplayOutput
def run(trace_input: TraceInput, config: ReplayConfig, tool_cache: ToolCache) -> ReplayOutput:
return ReplayOutput(text=f"replayed: {trace_input.user_message[:40]}", tool_spans=[], metadata={})
EOF
touch demo/__init__.py
# 2. Config — synthetic source + synthetic scorer; fully offline.
cat > whatifd.config.yaml <<'EOF'
source:
adapter: stub
target:
runner: "python:demo.runner:run"
selection:
failure_cohort: { limit: 20 }
baseline_cohort: { limit: 20 }
change:
system_prompt: "demo system prompt"
scorer:
adapter: stub
decision: {}
reporting:
profile: default
timeouts:
replay_seconds: 5.0
score_seconds: 5.0
EOF
# 3. Run.
PYTHONPATH=. whatifd fork --config whatifd.config.yaml
ls reports/ # whatifd-fork-*.json + whatifd-fork-*.md
cat reports/whatifd-fork-*.md
Analysis Verdict: Inconclusive¶
This produces an Inconclusive verdict with exit code 2.
The stub source ships empty by default; as a result, the Trust Floor refuses to render a Ship / Don’t Ship decision. This is by design to demonstrate that the framework’s core logic is functioning correctly.
Validation of the Five Cardinals¶
The demo confirms that the following principles are working end-to-end:
Cardinal #1 (Failure-as-Data): Failures are captured as structured data.
Cardinal #2 (Floor Constraints): The safety floor cannot be bypassed when data is missing.
Cardinal #5 (Graph Traversal): The walk runs against real
ReportV01JSON artifacts.Cardinal #10 (Methodology Disclosure): Full transparency is provided in the output.
Moving to Production¶
To produce actionable Ship / Don’t Ship verdicts on production traces, update your configuration:
Update Adapter: Change
source.adapter: stubtolangfuse.Point Runner: Direct your runner at a real agent.
Tip - Next steps follow the walk-through: Your first experiment
Why whatifd¶
When you change a prompt, model, or tool in an LLM system, you don’t actually know whether it improves behavior instead, you guess, with a handful of cherry-picked traces and inconsistent evaluation. Every step in the workflow has a tool: Langfuse for traces, Inspect AI for scoring, GitHub for PRs. The experiment doesn’t.
whatifd is the experiment runner;
Fork production traces (failed cases plus a representative baseline)
Replay them with your proposed change (original tool outputs cached so side effects don’t re-fire)
Score with Inspect AI, and produce a diff + verdict report you can attach to the PR.
You stop shipping changes that fix one failure while silently regressing ten others. You go from “this feels better” to “this improved 14 / 20, regressed 3, here’s exactly where, and here’s the evidence I’d defend in review.”
What you get¶
Fork the actual cases that motivated the fix, not synthetic golden sets that were green yesterday and stale today.
Original tool outputs are cached, so destructive side effects don’t re-fire. Live tool replay is opt-in with per-tool allowlists.
Every experiment runs a failures cohort and a baseline cohort by default. You catch the regression of previously-good traces, not just the rescue of bad ones.
Reports include the verdict, the stats, replay validity, baseline integrity, and concrete representative examples with judge rationale. Numbers without rationale are not trustworthy enough to ship from.
Markdown + JSON outputs, exit codes that reflect your declared decision policy, designed to be a PR check from day 1.
Bring your own tracer. Langfuse and Arize Phoenix / OpenInference ship as first-party adapters today; LangSmith and OpenTelemetry GenAI are on the v0.3+ roadmap. The runner contract makes the boundary clean.
Architecture¶
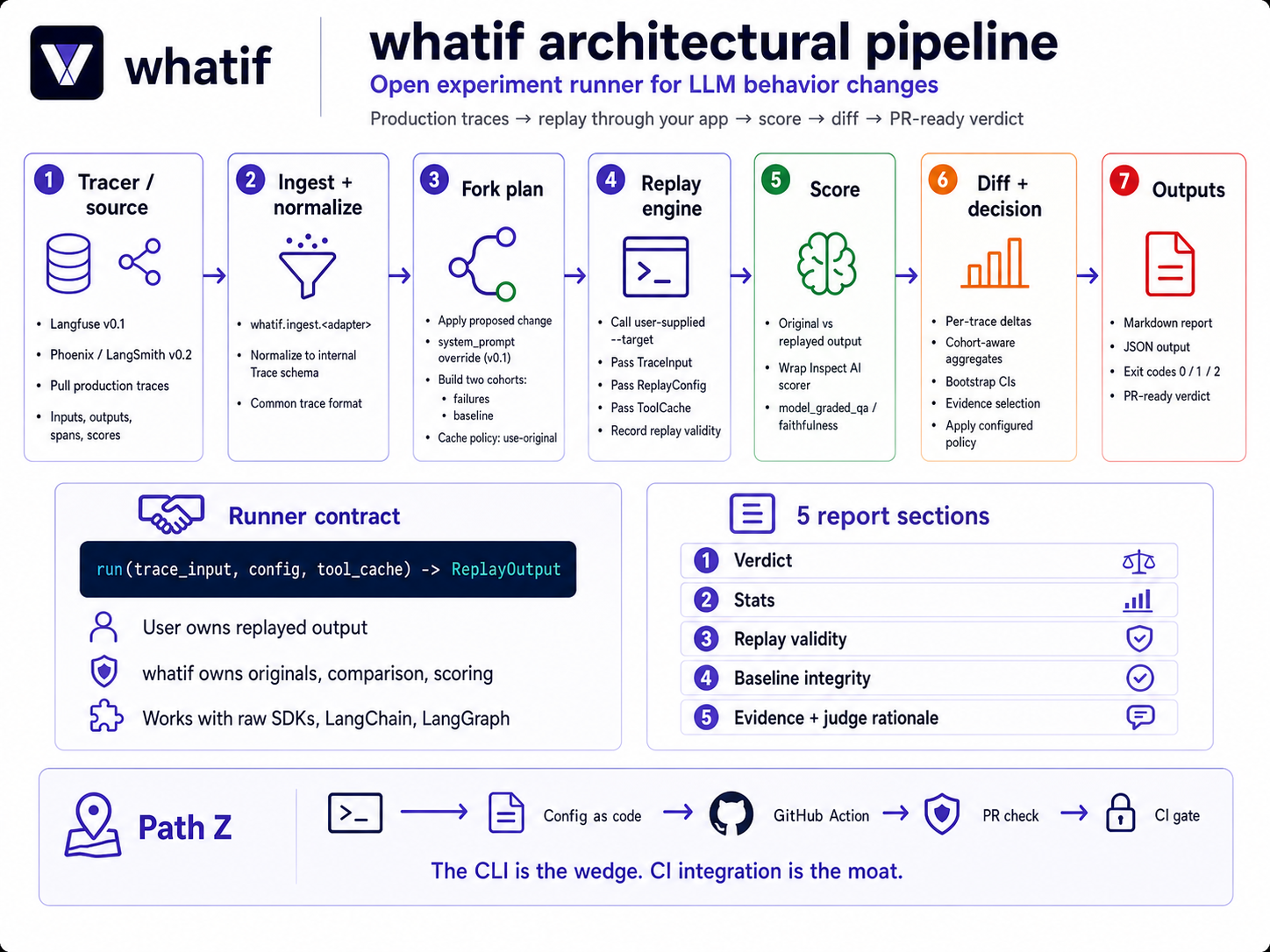
Read the runner contract deep-dive for how whatifd decomposes a --target runner contract from the rest of the system.
Status¶
whatifd v0.3.0 is on PyPI, the pre-merge regression gate for LLM behavior is laid out in the Path Z section.
Version |
Status |
What lands |
|---|---|---|
v0.1 |
shipped (2026-05-09) |
Failure-rescue experiments end-to-end. Langfuse ingest, cached-tool replay, Inspect AI scorer, six rendered walkthrough reports, trust floor + decision policy, methodology disclosure, |
v0.2 |
shipped (2026-05-10) |
Regression-check experiment shape; doctrinally-correct paired-percentile bootstrap (replaces the v0.1 empirical-quantile shortcut, with |
v0.3 |
shipped (2026-06-04) |
Datadog LLM Observability adapter ( |
roadmap |
planned |
Cluster-paired bootstrap; LangSmith adapter; marketplace publication of the GitHub Action; |
v1.0 |
year 2 |
The pre-merge regression gate for LLM behavior. |
whatifd supports two experiment shapes: failure_rescue (the v0.1 default — a known-bad set of traces plus a proposed fix, verdict on whether the fix rescues failures without regressing the baseline) and regression_check (a known-good baseline plus a candidate change, verdict on whether the change introduces regressions). Other shapes (exploratory A/B) remain deferred.